
My Attempt at Building a Multi-GPU Embedding Server with TEI and Qdrant
Github repo: https://github.com/joe32140/tei-qdrant-cache
Before We Start
Serving an LLM-based embedding model with replicates over multiple GPUs on the same machine might sound trivial today (2025), but after my extensive search, there’s actually no one-click setup. Originally, I thought vLLM could easily fulfill my needs, or that SGLang could be an alternative if vLLM didn’t work. However, both libraries turned out to be either very limited to specific models or did not support request routing across multi-GPUs. Luckily, I encountered link and link, leading me to an Nginx load balancer setup. It also turned out that Hugging Face has its own text-embeddings-inference library, which provides seamless support for serving embedding models with pre-built Docker images. In this post, my goal was to create a robust system for serving text embeddings using Hugging Face’s text-embeddings-inference (TEI) server, specifically targeting multi-GPU setups and incorporating a mechanism to handle repeated requests efficiently – essentially, building a smart caching layer.
The following sections detail the iterative process and the final architecture using TEI, FastAPI, Qdrant, Nginx, and Docker Compose.
The Initial Plan: Scaling TEI
The starting point was TEI, a high-performance server for embeddings. The immediate need was scaling across multiple GPUs (an 2-GPU machine in my case). TEI’s issue discussion suggested a pattern: run independent TEI instances, each pinned to a specific GPU, and place a load balancer like Nginx in front link.
To manage this, I opted for Docker Compose and wrote a Python script (generate_configs.py) to dynamically create the docker-compose.yml and nginx.conf based on a simple .env file specifying the number of GPU replicas (NUM_REPLICAS). This made scaling up or down much easier than manually duplicating service definitions.
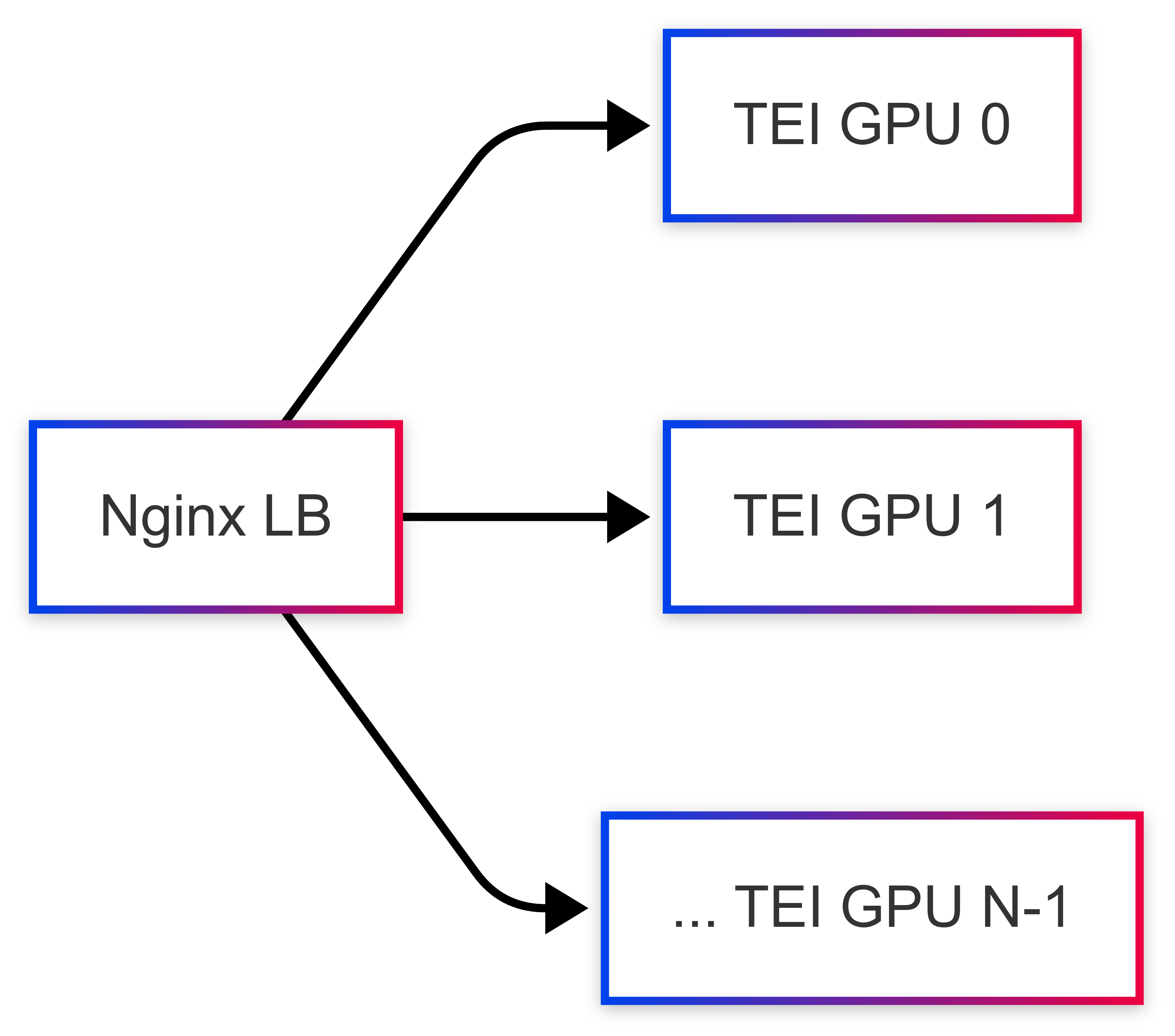
(Initial simplified view: Load Balancer distributing to TEI instances)
The Caching Idea: Handling Redundancy
With the basic multi-GPU serving working, the next goal was efficiency. Many applications send the same text for embedding multiple times. Re-computing these is wasteful. A caching layer was needed.
I considered options like Nginx+Lua but opted for a dedicated FastAPI proxy service placed in front of the Nginx load balancer. This offered better separation of concerns and more flexibility in implementing the caching logic. For the cache store itself, instead of a simple key-value store like Redis, I decided to experiment with Qdrant, a vector database. While slightly overkill for simple key-value lookups, it offered persistence and the potential for future vector-based operations on the cache itself.
The plan was:
- Client sends request to FastAPI proxy.
- Proxy hashes the input text to create a key.
- Proxy checks Qdrant for this key.
- Hit: Return cached embedding.
- Miss: Forward only the missed text(s) to Nginx -> TEI, get the embedding, store it in Qdrant, then return to the client.
The Final Stack & A Gradio Demo
After these iterations, the final architecture emerged:

(Simplified flow diagram)
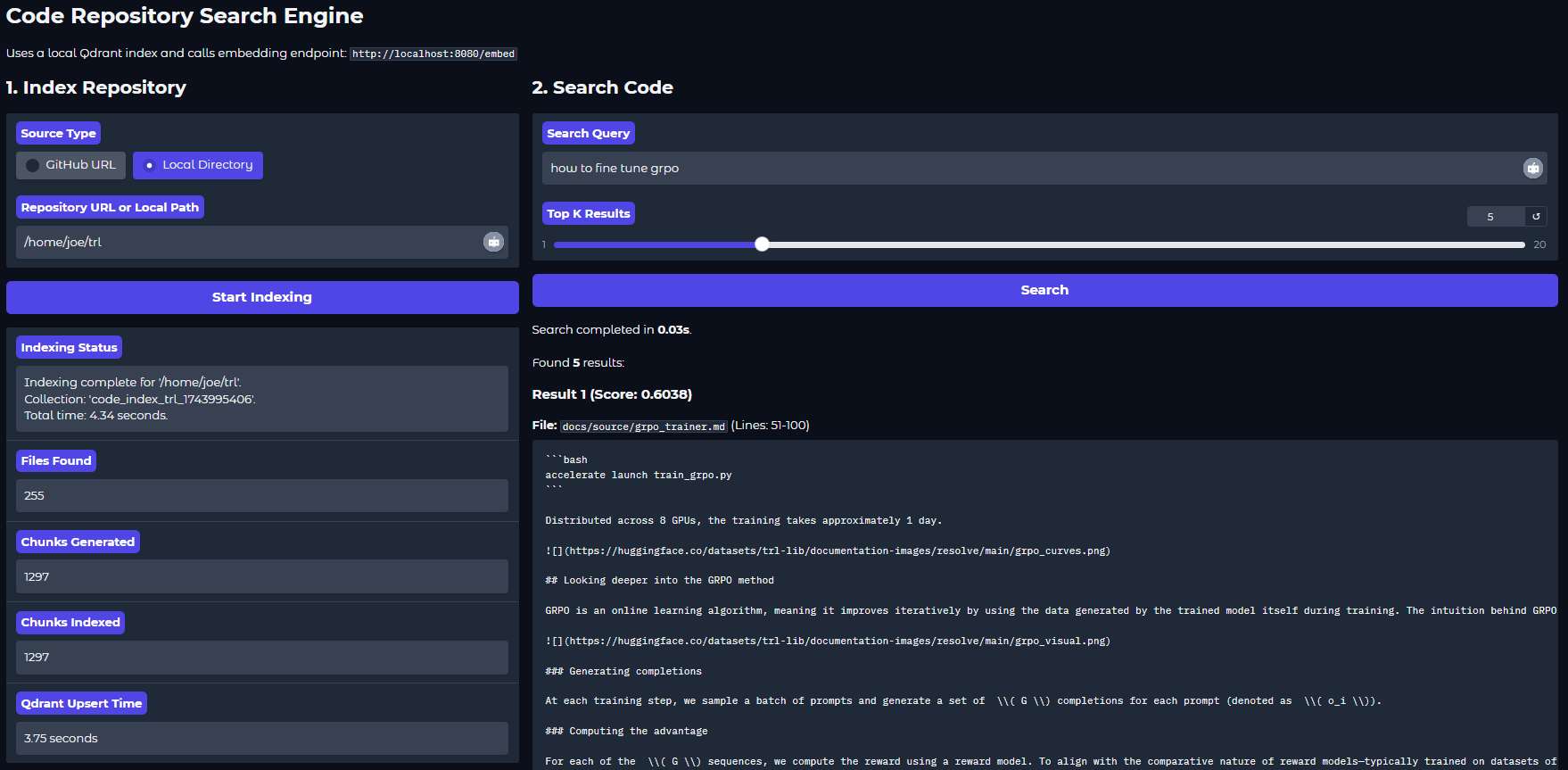
To make interaction easier, I added a simple Gradio application that uses this backend. It can clone a GitHub repo or scan a local directory, chunk code files, call the embedding endpoint (hitting the cache proxy), store the results in its own local Qdrant instance (separate from the main cache), and allow semantic search over the indexed code chunks. It works fine! (See the example below.)
Bottom Line & Takeaways
Building this tei-qdrant-cache system was a valuable journey through the practicalities of deploying and optimizing embedding models. Key takeaways include:
- Infrastructure First: Correct Docker, GPU driver, and NVIDIA Container Toolkit setup is paramount.
- Know Your Tools: Understand the requirements and limitations of components like TEI (model compatibility, token limits) and libraries like
qdrant-client(sync vs. async, ID formats). - Caching Benefits: A caching layer significantly improves performance for repeated inputs, but its implementation requires careful handling of cache misses and potential downstream bottlenecks.
- Batching is Key: When dealing with downstream services (like TEI) that have input size limits, implementing client-side batching in the proxy/application layer is essential.
- Iterative Development: Expect to hit roadblocks and refine the architecture based on errors and performance observations.
The final result is a scalable, persistent, and significantly faster embedding service for workloads with potential query repetition.
Check out the full implementation and try it yourself here https://github.com/joe32140/tei-qdrant-cache!